翻墙 免费 无界


2023 年,大型语言模型(LLM)以其强大的生成、理解、推理等能力而持续受到高度关注。然而,训练和部署 LLM 非常昂贵,需要大量的计算资源和内存,因此研究人员开发了许多用于加速 LLM 预训练、微调和推理的方法。
最近,一位名为 Theia Vogel 的博主整理撰写了一篇长文博客,对加速 LLM 推理的方法进行了全面的总结,对各种方法展开了详细的介绍,值得 LLM 研究人员收藏查阅。
这种推理方法很优雅,是 LLM 工作机制的核心。自回归 LLM 在只有数千个参数的情况下运行得很好,但对于实际模型来说就太慢了。为什么会这样,我们怎样才能让它更快?
从算法上讲,生成过程必须在每个周期处理越来越多的 token,因为每个周期我们都会将一个新 token 附加到上下文中。这意味着要从 10 个 token prompt 生成 100 个 token,需要在 10 + 11 + 12 + 13 + ... + 109 = 5950 个 token 上运行!(初始 prompt 可以并行处理,这就是为什么 prompt token 在推理 API 中通常更便宜的部分原因。)这也意味着模型在生成时会变慢,因为每个连续的 token 生成都有越来越长的前缀:
注意力(至少是普通注意力)也是一种二次算法:所有 token 都关注所有 token,导致 N^2 扩展,使一切变得更糟。
硬件原因是什么呢?很简单:LLM 规模很大。即使像 GPT-2 这样相对较小的模型也有 117M 参数,并且所有数据都必须存储在 RAM 中。RAM 确实很慢,现代处理器(CPU 和 GPU)通过在靠近处理器的地方设置大量高速缓存(cache)来弥补这一点,从而使访问速度更快。其细节根据处理器的类型和型号而有所不同,但关键是 LLM 权重不适合缓存,因此需要花费大量时间等待从 RAM 加载权重。这会产生一些不直观的效果!例如,即使激活张量(tensor)大 10 倍,对 10 个 token 进行操作也不一定比对单个 token 进行操作慢很多,因为主要的时间消耗在于移动模型权重,而不是进行计算。
不同的优化对这些指标的影响不同。例如,批处理可以提高吞吐量并更好地利用硬件,但会增加 TtFT 和生成延迟。
加速推理的一个直接方法就是购买更好的硬件(通常是某种加速器 ——GPU 或 TPU),或者更好地利用您拥有的硬件。
使用加速器可以显著提高速度,但请记住翻墙 免费 无界,CPU 和加速器之间存在传输瓶颈。如果模型不适合加速器的内存,则需要在整个前向传播过程中进行交换,这会大大减慢速度。这也是 Apple M1/M2/M3 芯片在推理方面表现出色的原因之一 —— 它们具有统一的 CPU 和 GPU 内存。
这些步骤每一个都很慢,并且某些步骤需要跨越 Python 和本机代码之间的界限。如果我使用 torch.compile 编译这个函数会怎样?
请注意,torch.compile 将上面的代码专门用于传入 ((10,)) 的张量的特定大小。如果我们传入许多不同大小的张量,torch.compile 将生成超过该大小的通用代码,但具有恒定大小可以使编译器在某些情况下生成更好的代码。
该函数具有数据相关的控制流,这意味着我们会根据变量的运行时值执行不同的操作。如果以与编译 foo 相同的方式编译它,我们会得到两个图(因此有两个 debug 目录):
这就是所谓的「graph break」,这会让编译后的函数变慢,因为必须离开优化后的内核并返回到 Python 来评估分支。最重要的是,另一个分支(return r + torch.tan (x))尚未编译,因为它尚未被采用。这意味着它将在需要时动态编译,在不合适的时间(例如在服务用户请求的过程中)就会很糟糕。
像 torch.compile 这样的工具是优化代码以获得更好的硬件性能,而无需使用 CUDA 编写内核。
为了批量生成,我们一次向模型传递多个序列,在同一次前向传递中为每个序列生成一个补全。这需要使用填充 token 在左侧或右侧将序列填充到相等的长度。填充 token(这里使用 [end])被隐藏在注意力掩码中,这样它们就不会影响生成。
由于以这种方式批处理序列允许模型权重同时用于多个序列,因此一起运行整批序列比单独运行每个序列花费的时间更少。例如,在我的机器上,使用 GPT-2 生成下一个 token:
在上面的示例中,「Mark is quick. He moves quickly.」在其他序列之前完成,但由于整个批次尚未完成,我们需要继续为其生成 token(Random)。
连续批处理通过在其他序列完成时在其 [end] token 之后将新序列插入批处理来解决此问题。
浮点数有不同的大小,这对性能很重要。大多数情况下,对于常规软件,我们使用 64 位(双精度)IEEE 754 浮点,而 ML 传统上使用 32 位(单精度)IEEE 754:
模型使用 fp32 进行良好的训练和推理,这为每个参数节省了 4 个字节 (50%),这个影响是巨大的,例如 7B 参数模型在 fp64 中将占用 56Gb,而在 fp32 中仅占用 28Gb。训练和推理期间的大量时间都花在将数据从 RAM 移动到缓存和寄存器上 —— 移动的数据越少越好。
在减少 fp32 的字段时,fp16 和 bfloat16 进行了不同的权衡:fp16 试图通过缩小指数和分数字段来平衡范围和精度,而 bfloat16 通过保留 8 位指数来保留 fp32 的范围,同时将分数字段缩小到小于 fp16,损失了一些精度。范围损失有时可能会成为 fp16 训练的问题,但对于推理来说,两者都可以,如果 GPU 不支持 bfloat16,fp16 可能是更好的选择。
一种方法是量化以更大格式(例如 fp16)训练的模型。llama.cpp 项目(以及相关的 ML 库 ggml)定义了一整套量化格式。
这些量化的工作方式与 fp16 /bfloat16 略有不同 - 没有足够的空间来容纳整个数字,因此权重以块为单位进行量化,其中 fp16 充当块尺度(scale),然后量化块每个权重都乘以该尺度。
然而,使用更广泛的参数训练的模型量化越小,它就越有可能影响模型的性能,从而降低响应的质量。因此我们要尽可能少地采用量化,才能获得可接受的推理速度。
但我们也可以使用小于 fp16 的数据类型来微调或训练模型,例如使用 qLoRA 训练量化低阶适配器。
在 Transformer 内部,激活通过前馈层生成 qkv 矩阵,其中每一行对应一个 token:
现在,根据该层在 Transformer 中的位置,这些行可能会(在通过 MLP 之后)用作下一个 Transformer 块的输入,或者作为下一个 token 的预测,但请注意,每个 token 都有一行!这是因为 Transformer 经过训练可以预测上下文窗口中每个 token 的下一个 token。
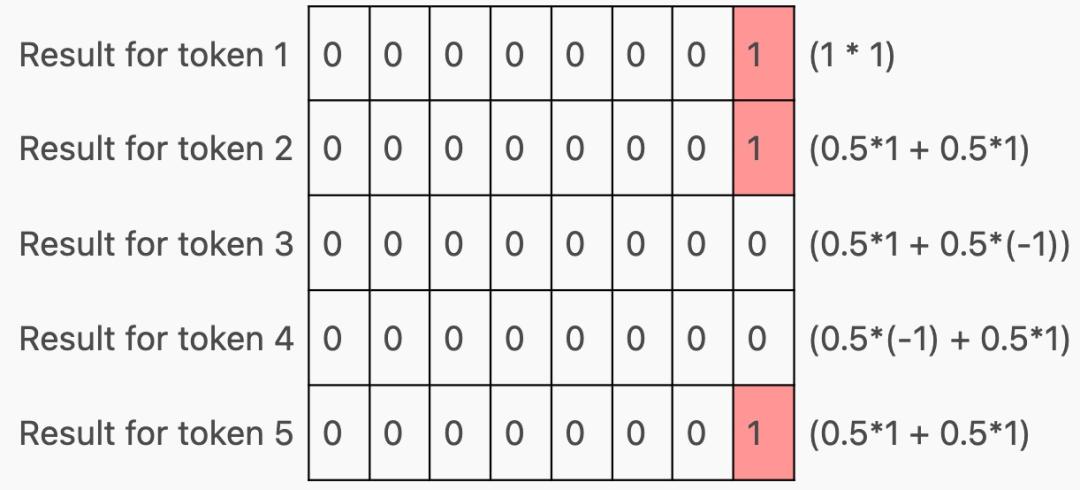
在训练过程中,这种行为是可取的 —— 这意味着更多的信息正在流入 Transformer,因为许多 token 都被评分。但通常在推理过程中,我们关心的只是底行,即最终 token 的预测。
我们如何才能从经过训练来预测整个上下文的 Transformer 中得到这一点呢?让我们回到注意力的计算。如果 q 只有一行(对应于最后一个 token 的行)怎么办?
在模型内部,我们将注意力期间计算的 KV 值保存在每个 Transformer 块中。然后在下一次生成时,只传入单个 token,并且缓存的 KV 行将堆叠在新 token 的 KV 行的顶部,以产生单行 Q 和多行 KV。
KV cache 有助于解决 LLM 缓慢的问题,因为现在每个步骤中只传递一个 token,所以我们不必为每个新 token 重做所有事情。然而,KV cache 的大小仍然每一步都会增长,从而减慢了注意力计算的速度。
KV cache 的大小也会带来自己的新问题,例如,对于 1000 个 token 的 KV cache,即使使用最小的 GPT-2,也会缓存 18432000 个值。如果每个值都是 fp32,那么单次生成的缓存几乎为 74MB。对大模型来说,尤其是在需要处理许多并发客户端的服务器上运行的模型,KV cache 很快就会变得难以管理。
多查询注意力(Multi-Query Attention,MQA)是对模型架构的改变,通过为 Q 分配多个头,为 K 和 V 只分配一个头来缩小 KV 缓存的大小。值得注意的是,使用 MQA 的模型比使用普通注意力训练的模型可以支持 KV 缓存中更多的 token。
大型 KV cache 的另一个问题是,它通常需要存储在连续的张量中,无论当前是否所有缓存都在使用。这会导致多个问题:
PagedAttention 会为请求分配一个块表(block table),类似于内存管理单元(MMU)。每个请求没有与大量 KV 缓存项相关联,而是仅具有相对较小的块索引列表,类似于操作系统分页中的虚拟地址。这些索引指向存储在全局块表中的块。
首先,由于内存访问开销,模型运行少量 token 所需的时间与运行单个 token 大约相同:
最后,有些词很容易预测。例如,在单词「going」之后,单词「to」极有可能是下一个 token。
我们只需要使用一个足够小的「draft 模型」(运行速度足够快),并使用相同的 tokenizer,以避免需要一遍又一遍地对序列进行 detokenize 和 retokenize。
然而,猜测解码的性能可能非常依赖于上下文!如果 draft 模型与 oracle 模型相关性很好,并且文本很容易预测,那么您将获得大量 draft token 和快速推理。但如果模型不相关,猜测解码实际上会使推理速度变慢,因为要浪费时间生成将被拒绝的 draft token。
一种缓解使用固定数量 draft token 问题的方法是「阈值解码」—— 并不总是解码最大数量的 draft token,而是保留一个移动概率阈值,根据当前的 token 数量进行校准。draft token 会一直生成,直到 draft 的累积概率低于此阈值。
例如,如果阈值是 0.5,并且我们以 0.75 的概率生成 draft token「the」,继续下去。如果下一个 token「next」的概率为 0.5,则累积概率 0.375 将低于阈值,因此会停止生成并将两个 draft token 提交给 oracle 模型。然后,根据 draft 被接受的程度,向上或向下调整阈值,以尝试用实际接受率来校准 draft 模型的置信度。
语法指导型生成可约束模型的输出遵循某些语法,从而提供保证匹配某些语法(例如 JSON)的输出。这对模型推理的可靠性和速度都有益。
前向解码是一种新的猜测解码方法,不需要 draft 模型。相反,模型本身用于两个分支:预测和扩展候选 N-gram 的前向分支和验证候选的验证分支。前向分支类似于常规猜测解码中的 draft 模型,而验证分支与 oracle 模型具有相同的作用。
最后,作者从稀疏注意力(sparse attention)和非 Transformer 架构两个方面简单阐述了训练时间优化的方法。感兴趣的读者可以阅读博客原文,了解更多内容细节。